Yesterday, I came across whisper.cpp, which is a C/C++ implementation for OpenAI’s Whisper, an open source, automatic speech recognition (ASR) neural network. It’s simple enough to use, beyond the slightly clunky C-like API, and produces great results, of generating text, based on audio data of spoken words, and that without requiring a connection to some online language model cluster.
After trying the WASM demo in the browser, I had the idea to use SFML as audio input provider. The final goal would be to have the microphone input directly feed into whisper.cpp and thus get Speech-To-Text (STT) in near real-time. As getting this all setup, understood and connected takes a bit more time, than just a few hours in the evening, I opted for a basic audio file loading for now.
The repository can be found here: https://github.com/eXpl0it3r/WhisperSFML
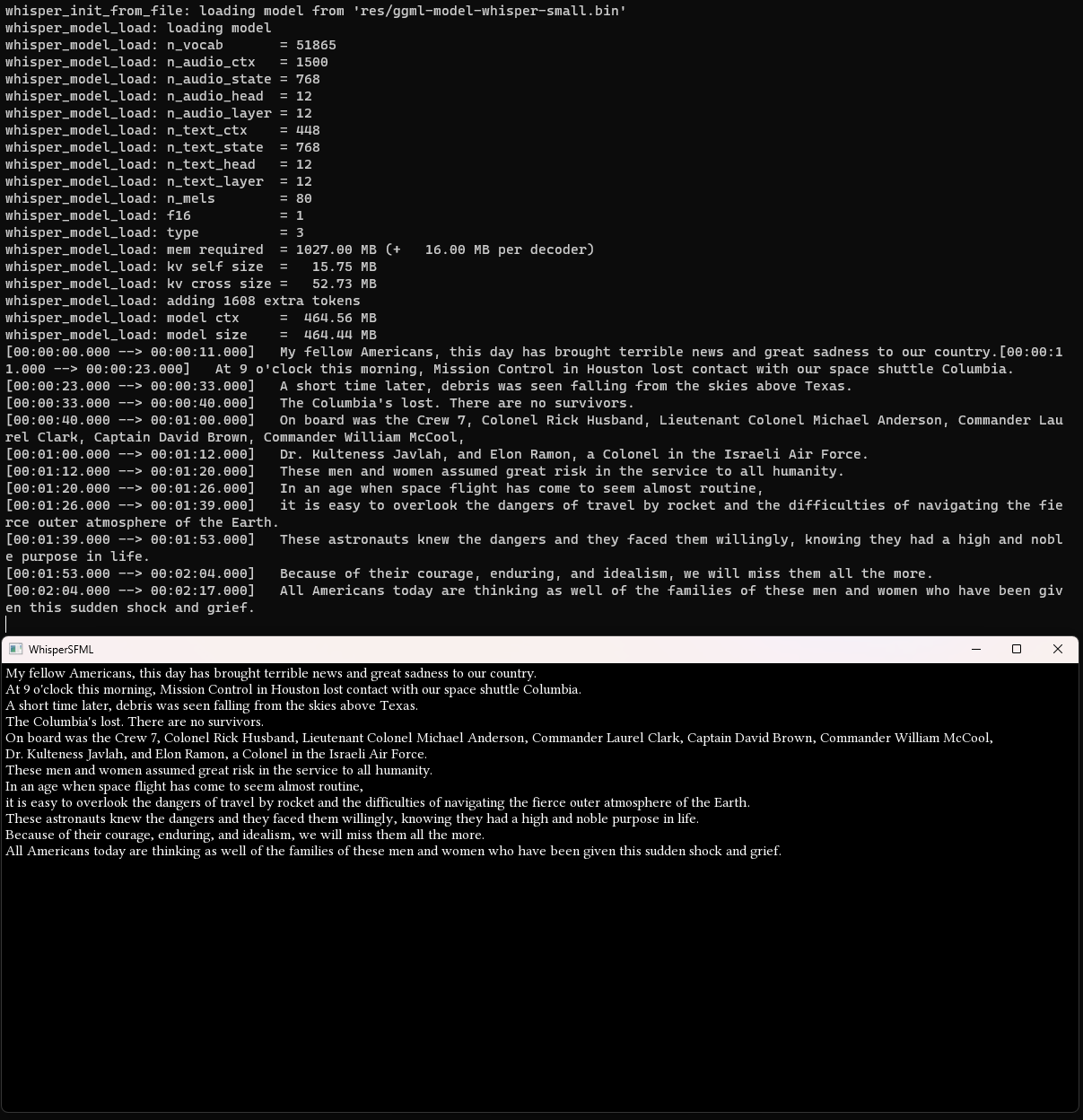
However, since I’ll be updating the contents over the next couple of days/weeks, I’ll post the basic code snippets below with some comments, so future readers will also get a glimpse at the current state.
Loading sound data is really quite simple with SFML, so I won’t get into more details here – just look at the official tutorial – what cost me a bit of time, was figuring out, how to convert the signed 16bit audio buffer from SFML into a 32bit float buffer, which whisper.cpp requires. After browsing the web and looking at different whisper.cpp examples, and finally realizing that I also need to account for stereo audio, I managed to come up with a conversion function like so:
std::vector<float> convertTo32BitFloat(const sf::SoundBuffer& buffer)
{
auto* const samples = buffer.getSamples();
auto convertedSamples = std::vector<float>{};
convertedSamples.reserve((buffer.getSampleCount() + 1) / 2);
if (buffer.getChannelCount() == 2)
{
for (auto i = 0u; i < buffer.getSampleCount(); i += 2)
{
convertedSamples.push_back(static_cast<float>(samples[i] + samples[i + 1]) / 65536.0f);
}
}
else
{
for (auto i = 0u; i < buffer.getSampleCount(); ++i)
{
convertedSamples.push_back(static_cast<float>(samples[i]) / 65536.0f);
}
}
return convertedSamples;
}
The magic number 65536 represents the max size for a 32bit float. I’ve no idea if that’s a good conversion “algorithm”, or whether it would need some additional audio processing. Let me know if you have some good sources to learn about this.
After we’ve convert the audio data, we can move over to using whisper.cpp, which essentially requires four steps:
- Initialize whisper.cpp with a model file to get a context
- Run the analysis
- Retrieve the generated text segments for further use
- Free the context at the end
auto samples = std::vector<float>{};
auto* context = whisper_init_from_file("ggml-model-whisper-small.bin");
auto parameters = whisper_full_default_params(WHISPER_SAMPLING_GREEDY);
whisper_full(context, parameters, samples.data(), samples.size());
const int numberOfSegments = whisper_full_n_segments(context);
for (int i = 0; i < n_segments; ++i)
{
auto segment = whisper_full_get_segment_text(context, i);
}
whisper_free(context);
There are some parameters you can play around with and there are differently sized models to use. The Tiny model didn’t manage to properly parse the example audio, but the Small model worked great.
Conclusion
Once you understand the whisper.cpp API and how to get the data into the correct format, it’s quite simple to use, and delivers great results. In release mode with eight threads active, it lags behind the playback for a few seconds at first, but then easily overtakes the real-time playback with spitting out the generated text segments.
I was surprised that it correctly detects most of the names. For some of the non-English names, it produces a wrong spelling, e.g. Kalpana Chawla became Kulteness Javlah. Might be that since the audio is spoken in English, it has a context for English names and fails to consider a spelling in a different language context. Might have to give the Medium or Large models a try, to see if they do better.
Wishper.cpp already provides an streaming example with SDL2, but I’ll try and see to rewrite this with SFML. It’s a bit more tricky, thus I didn’t manage to get it implemented in time, as you have to synchronize three different threads: Audio recording, whisper.cpp processing and graphics rendering.
3 thoughts on “Using Open AI’s Whisper With SFML”